

Hello, Everyone!
In 2017, everything was looking up for Ethereum — ETH was soaring, developers were coming in droves to build (this was before buidl) new dApps, and enterprises were getting involved. But the success would prove too great for Ethereum to handle…

Yeah… that transaction is going to take a few days at that gas price.
If you were around at the time, you remember it all too well - Cryptokitties had just been released and was rapidly rising in popularity to become the first majorly successful dApp. And this success was exactly what caused it (and others) to hog all of Ethereum’s resources — causing the chain’s mempool to grow at an unprecedented rate.
The worry didn't get much time to set in as Plasma and State Channels were on the horizon as the solutions to our scaling woes. But despite all of the talk and excitement, development moved at a glacial pace and some members of the community started having their doubts as to the feasibility of these solutions. But now, as things begin coming online, people are seeing what has kept implementers at bay for so long — this is, of course, the illustrious data availability problem.
In this article, we’ll be giving a bit of background on the data availability problem and how it is being addressed by various layer two solutions such as Plasma, State Channels, and Elastic Sidechains (aka SKALE Chains).
As Vitalik has previously explained it, the data availability problem is where a malicious miner publishes a block where the blockheader is present but some or all of the block data is missing. This can:
- Convince network to accept invalid blocks and there’s no way to prove invalidity.
- Prevent nodes from learning the state.
- Prevent nodes from being able to create blocks or transactions because they lack the information to construct the proofs.
And this problem doesn’t just relate to the withholding of block data. Generally speaking, it’s where any data is withheld from other participants in the network, a.k.a. censorship - one of the main issues which blockchain was created to address. So, naturally, this isn't an issue on the mainnet (as far as we’re aware), but it has come at great cost. In fact, the past 18 months, we’ve seen a 6.5x increase in the amount of state stored on each Ethereum node (GETH w/ FAST Sync).
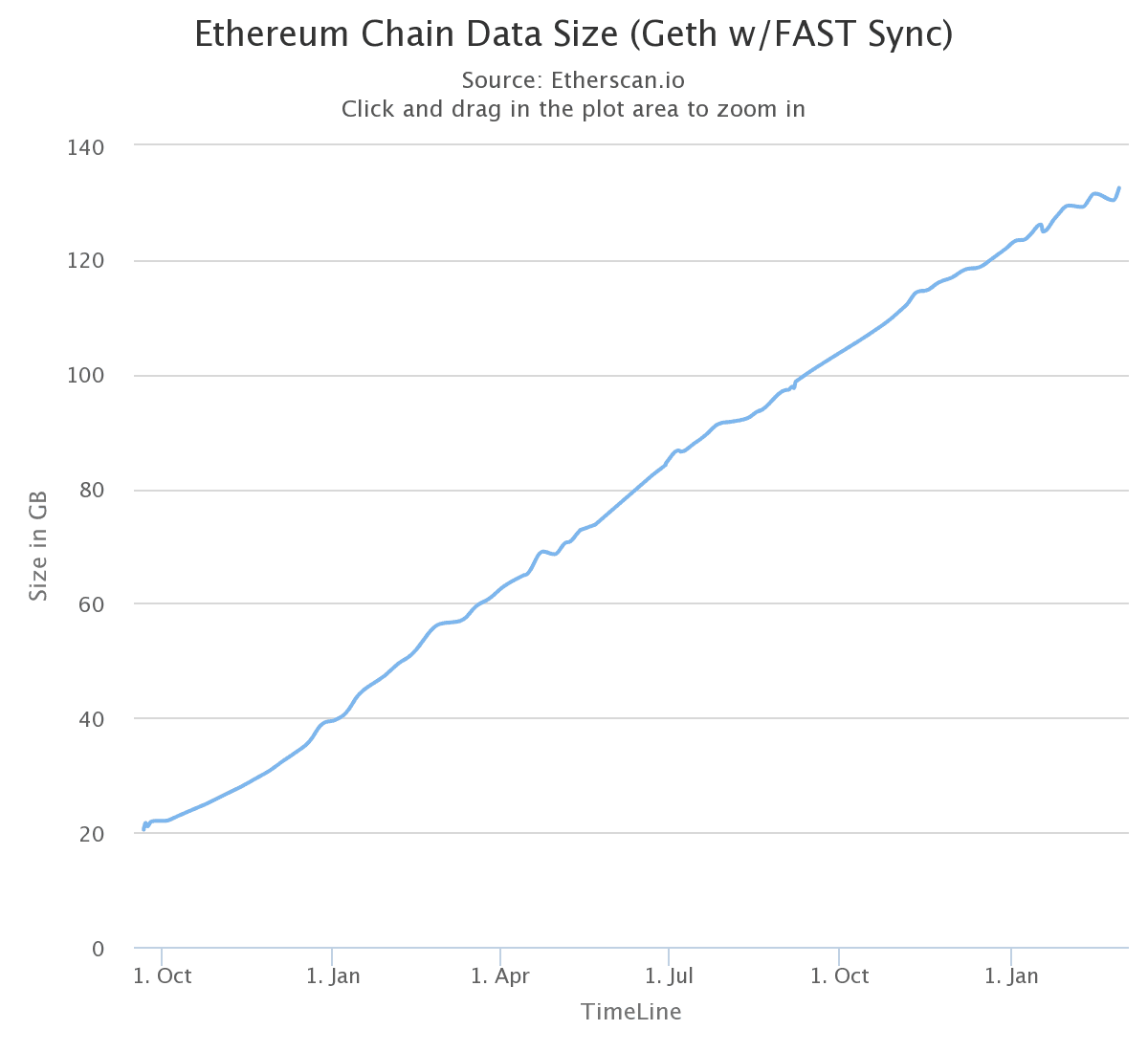
And clearly, this is unsustainable as participants will need more and more powerful computers with greater amounts of storage to continue participating in the network, leading to centralization. So, how do we combat this rapidly growing chain?
That's easy - just offload everything that doesn't need to be on-chain to the clients! In this way, we start and end things on-chain, but do all of the intermediate transactions off-chain. Which is the basic idea behind all Execution Layer / Layer 2 scaling solutions.
We go from everything being on-chain to the chain only serving as a settlement layer for off-chain interactions. But now we face the problem of clients being required to maintain all of these off-chain transactions relating to them or be at the mercy of whomever does.
Imagine you go to a casino to play blackjack. When you walk in, you go to a counter and exchange dollars for poker chips (think of this as an on-chain transaction). You then proceed to go to a table and play blackjack for a few hours (think of these as off-chain transactions) — sometimes you’re up, other times you’re down. After winning a huge hand, you tell the table you’re going to go cash out.
Now, as you get up from the table, someone hits you over the back of the head with a crowbar. This causes you to lose your memory of the blackjack game (this is data unavailability). While you were out, the people at the table decided to pretend like the last hand didn’t happen and continued playing from where they had been prior to the hand — cheating you of money that you had won.
For a blackjack game which is fully on-chain, this sort of cheating wouldn’t be possible. But because it was all off-chain and you lost your transaction history, you have to accept the history that your peers tell you.
With Plasma, you can think of every participant running a node which only cares about their transactions where they store their entire transaction history as well as enough witness data to prove whether or not their cryptoassets were transacted with in every Plasma block. The reasoning for this history requirement is the fact that anyone in the Plasma instance could collude with the chain’s operator to submit invalid transactions to attempt the stealing of funds from other participants. And the only way for participants to prevent this from happening is to ensure that they have a complete and valid transaction history for all of their assets.
State channels show improvement over this in that they can be resolved in one transaction instead of having to replay all transaction history. This is due to the fact that all parties are agreeing upon the current state instead of a state update (ex: transaction). And because each state has an auto-incrementing nonce and is not regarded by the smart contract as valid unless it has signatures from both parties, participants only need to store the latest state.
Note: Participants in a state channel may wish to store history state, as well, to settle with an earlier and more advantageous state in the case that their counterparty loses their state history.
So, to say that data availability is a 'problem' is a bit of a misnomer. It's more like a constraint in that there is no perfect solution. There are much better solutions that are being worked on such as ZK-SNARKS and RSA Accumulators, but they don’t fix data availability. Any solution which addressed this problem would require that a client be online 100% of the time and never lose data stored on it (sounds a lot like a blockchain, right?).
But given that these machines don’t really exist, the general consensus for addressing data availability is through incentivized watchtower networks (ex: PISA) or similar constructs. If you'd like to learn more about them, please check them out, here!
In short, these networks are arrays of staked watchtowers who back up data and will dispute any challenges on behalf of users who pay them rent for their service. If they fail to dispute a challenge within a certain time-period, they will lose their stake and it will be awarded a new watchtower in the network assigned to dispute the challenge (assuming it does). This failure / appointment protocol is multiple layers deep, so users have some assurance that they will not be cheated in the case that they fall offline or lose their transaction / state history.
SKALE’s SKALE Chain approach address the data availability problem with their block proposal process. Once a virtualized subnode creates a block proposal it will communicate it to other virtualized subnodes using the data availability protocol described below. The data availability protocol guarantees that the message is transferred to the supermajority of virtualized subnodes.
The five-step protocol is described below:
- The sending virtualized subnode A sends both the block proposal and the hashes of the transactions which compose the proposal P to all of its peers.
- Upon receipt, each peer will reconstruct P from hashes by matching hashes to transactions in its pending queue. For transactions not found in the pending queue, the peer will send a request to the sending virtualized subnode A. The sending virtualized subnode A will then send the bodies of these transactions to the receiving virtualized subnode, allowing for the peer to reconstruct the block proposal and add the proposal to its proposal storage database PD.
- The peer then sends a receipt to back to A that contains a threshold signature share for P.
- A will wait until it collects signature shares from a supermajority (>⅔) of virtualized subnodes (including itself) A will then create a supermajority signature S. This signature serves as a receipt that a supermajority of virtualized subnodes are in possession of P.
- A will then broadcast this supermajority signature S to each of the other virtualized subnodes in the network.
Note: Each virtualized subnode is in possession of BLS private key share PKS[I]. Initial generation of key shares is performed using Joint-Feldman Distributed Key Generation (DKG) algorithm which occurs at the creation of the SKALE Chain and whenever virtualized subnodes are shuffled.
In further consensus steps, a data availability receipt is required by all virtualized subnodes voting for proposal P whereby they must include supermajority signature S in their vote; honest virtualized subnodes will ignore all votes that do not include the supermajority signature S. This protocol guarantees data availability, meaning that any proposal P which wins consensus will be available to any honest virtualized subnodes.
For the past 18+ months, this is what developers working on the execution layer have been occupying the majority of their time trying to address. And while there is no perfect solution to this for all scaling solutions (yet), there’s a lot of new and exciting work being done and we are excited to see what the future brings!
If you are interested in trying SKALE out, make sure to join the SKALE community on Discord and check out the Developer Documentation! Also, feel free to also check out SKALE’s Technical Overview and Consensus Overview for a deeper dive into how SKALE works and is able to provide 20,000 TPS.
SKALE’s mission is to make it quick and easy to set up a cost-effective, high-performance SKALE Chain that runs full-state smart contracts. We aim to deliver a performant experience to developers that offers speed and functionality without giving up security or decentralization. Follow us here on Telegram, Twitter, Discord, and sign up for updates via this form on the SKALE website.


