

If you use the Internet, it’s highly likely that you recall the various times that major sites like Reddit, Netflix, Instagram, Airbnb, and others fell offline. And when each of these businesses is completely dependent on AWS for their infrastructure, it is pretty hard to miss the various failures over the years. And even though preventative measures (e.g. load balancing) are put in place to mitigate such disasters, there’s really nothing that can be done when the hosting provider goes down.
To the defense of AWS, these failures have been reasonably spaced out and minor, in the grand scheme of things. But, as the world continues to be eaten by software, they are having larger and larger implications. When you consider a future where autonomous cars’ software is run on this sort of architecture, failure (even if just for a minute) is completely unacceptable. And it’s this future mindset of disintermediation that has led the blockchain movement to take hold in an attempt to improve on the existing standard.
While many scoff at the idea of providing uptime guarantees that exceed those of Amazon’s AWS, this is not a bold of a claim to those in the decentralized community. In fact, Bitcoin just hit 10 years of nonstop block production — something very few services as large can tout.
But people inside of the blockchain community know that this liveness comes at the cost of scalability. This is especially true of blockchains which use Proof of Work as a means by achieving consensus. So, we see efforts in the realm of developing more efficient consensus as well as the emergence of second layer solutions taking value from one of the main Proof of Work chains and using that to fund state channels, plasma, elastic sidechains, etc... And while each of these scaling solutions has its caveats in terms of security, efficiency, capital lockup, and data availability, we believe that SKALE is best possible decentralized scaling solution for Ethereum's 'Execution Layer'.
In this article, we detail how we have managed to address these concerns by combining best in class proven research with world-class engineering to create a consensus mechanism which can run over 20,000 TPS in a standalone environment and thousands of TPS in a fully connected Ethereum environment with average blocktimes of 1–2 seconds.
Note: If you have not read our brief technical overview, read it for more context before continuing.
The protocol assumes that the network is asynchronous with eventual delivery guarantee, meaning that all virtualized subnodes are assumed to be connected by a reliable communications link - links can be arbitrarily slow, but will eventually deliver messages.
This asynchronous model is similar to Bitcoin and Ethereum blockchains and reflects the state of modern Internet, where temporary network splits are normal, but eventually resolve. The eventual delivery guarantee is achieved in practice by the sending virtualized subnode making multiple attempts with exponential backoff to transfer the message to the receiving virtualized subnode, until the transfer is successful.
Each virtualized subnode maintains pending transactions queue. The first virtualized subnode to receive a transaction into that queue will attempt to propagate it to its peers via dedicated outgoing message queues for each. To schedule a message for delivery to a particular peer, it is placed into the corresponding outgoing queue. Each of these outgoing queues is serviced by a separate thread, allowing messages to be delivered in parallel so that failure of a particular peer to accept messages will not affect receipt of messages by other peers.
After the previous consensus round has been completed, each virtualized subnode’s TIP_ID will increment by 1 and immediately cause them to create a block proposal.
To create a block proposal, a virtualized subnode will:
- Examine its pending transaction queue.
- If the total size of transactions in the pending queue is less than or equal to the MAX_BLOCK_SIZE, the virtualized subnode will fill in a block proposal by taking all transactions from the queue.
- In the case that the total size of transactions in the pending queue exceeds MAX_BLOCK_SIZE, the virtualized subnode will fill in a block proposal of MAX_BLOCK_SIZE by taking pending transactions from queue in order of oldest to newest received.
- The virtualized subnode will assemble block proposals with transactions which are ordered by SHA-256 Merkle root from smallest value to largest value.
- In the case that the pending queue is empty, the virtualized subnode will wait for BEACON_TIME, and then, if the queue is still empty, make an empty block proposal containing no transactions.
Note: Virtualized subnodes do not remove transactions from the pending queue at the time of proposal. The reason for this is that at the proposal time there is no guarantee that the proposal will be accepted.
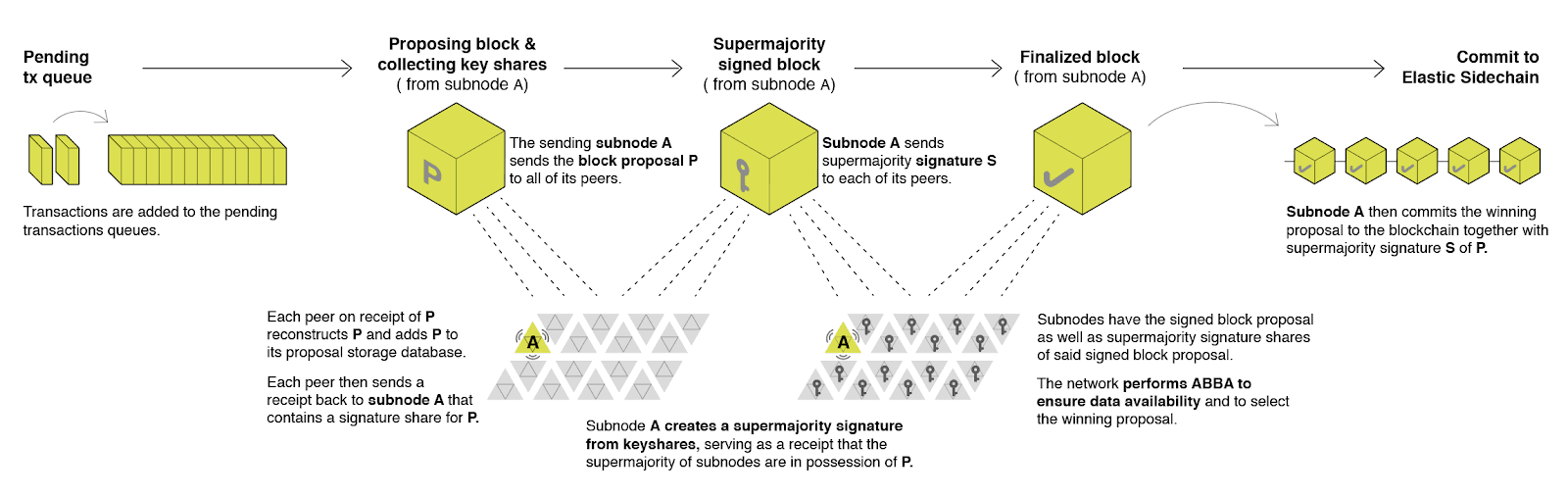
Once a virtualized subnode creates a block proposal it will communicate it to other virtualized subnodes using the data availability protocol described below. The data availability protocol guarantees that the message is transferred to the supermajority of virtualized subnodes.
The five-step protocol is described below:
- The sending virtualized subnode A sends both the block proposal and the hashes of the transactions which compose the proposal P to all of its peers.
- Upon receipt, each peer will reconstruct P from hashes by matching hashes to transactions in its pending queue. For transactions not found in the pending queue, the peer will send a request to the sending virtualized subnode A. The sending virtualized subnode A will then send the bodies of these transactions to the receiving virtualized subnode, allowing for the peer to reconstruct the block proposal and add the proposal to its proposal storage database PD.
- The peer then sends a receipt to back to A that contains a threshold signature share for P.
- A will wait until it collects signature shares from a supermajority (>⅔) of virtualized subnodes (including itself) A will then create a supermajority signature S. This signature serves as a receipt that a supermajority of virtualized subnodes are in possession of P.
- A will then broadcast this supermajority signature S to each of the other virtualized subnodes in the network.
Note: Each virtualized subnode is in possession of BLS private key share PKS[I]. Initial generation of key shares is performed using Joint-Feldman Distributed Key Generation (DKG) algorithm which occurs at the creation of the SKALE Chain and whenever virtualized subnodes are shuffled.
In further consensus steps, a data availability receipt is required by all virtualized subnodes voting for proposal P whereby they must include supermajority signature S in their vote; honest virtualized subnodes will ignore all votes that do not include the supermajority signature S. This protocol guarantees data availability, meaning that any proposal P which wins consensus will be available to any honest virtualized subnodes.
The consensus described below uses an Asynchronous Binary Byzantine Agreement (ABBA) protocol. We currently use a variant of ABBA derived from Mostefaoui et al. Any other ABBA protocol P can be used, as long as it satisfies the following properties:
- Network model: P assumes asynchronous network messaging model described above.
- Byzantine nodes: P assumes less than one third of Byzantine nodes.
- Initial vote: P assumes that each node makes an initial vote yes(1) or no(0)
- Consensus vote: P terminates with a consensus vote of either yes or no, where if the consensus vote is yes, it is guaranteed that at least one honest node voted yes.
Note: An ABBA protocol typically outputs a random number COMMON_COIN as a byproduct of its operation. We use this COMMON_COIN as a random number source.
Immediately after the proposal phase completes, each virtualized subnode A who has received supermajority signature S for their proposal P will vote for Asynchronous Byzantine Binary Agreements (ABBAs) in a consensus round R. The protocol is as follows:
- For each R, virtualized subnodes will execute N instances of ABBA.
- Each ABBA[i] corresponds to a vote on block proposal from the virtualized subnode i.
- Each ABBA[i] completes with a consensus vote of yes or no.
- Once all ABBA[i] complete, there is a vote vector v[i], which includes yes or no for each proposal.
- If there is only one yes vote, the corresponding block proposal P is committed to the SKALE Chain.
- If there are multiple yes votes, P is pseudorandomly picked from the yes-voted proposals using pseudorandom number R. The winning proposal index the remainder of division of R by N_WIN, where N_WIN is the total number of yes proposals.
- The random number R is the sum of all ABBA COMMON_COINs.
- In the rare case where all votes are no, an empty block is committed to the blockchain. The probability of an all-no vote is very small and decreases as N increases.
Once consensus completes with winning block proposal P on any virtualized subnode A, the virtualized subnode will execute the following algorithm to finalize the proposal and commit it to the chain:
- A will check if it has received the winning proposal P.
- If A has not received the proposal, it will request it from its peer virtualized subnodes for download.
- A will then sign a signature share S for P and send it to all other virtualized subnodes.
- A will then wait to receive signature shares from a supermajority of virtualized subnodes, including itself.
- Once A has received a supermajority of signature shares, it will combine them into a threshold signature.
- A will then commit the P to the blockchain together with the threshold signature S.
Blocks which are committed to the SKALE Chain contain a block header and block body. The block body is a concatenated transactions array of all transactions in the block and the block header is a JSON object.
During a reboot, the rebooting node will become temporarily unavailable — for peer nodes, this will look like a temporarily slow network link. After a reboot, messages destined to the node will be delivered — this protocol allows for a reboot to occur without disrupting the operation of consensus.
In the case of a hard crash where a node loses consensus state due to a hardware failure or software bug that prevents the node from being online, its peers will continue attempting to send messages to it until their outgoing messages queues overflow — causing them to drop older messages. To mitigate the effects of this, messages older than one hour are targeted to be dropped from message queues.
While a node is undergoing a hard crash, it is counted as a Byzantine node for each consensus round — allowing for <⅓ of nodes to be experiencing hard crashes simultaneously. In the case where >⅓ nodes experience a hard crash, consensus will stall, causing the blockchain to possibly lose its liveness.
Such a catastrophic failure will be detected through the absence of new block commits for a set time period. At this point, a failure recovery protocol utilizing the Ethereum main chain for coordination will be executed. Nodes will stop their consensus operation, sync their blockchains, and agree on time to restart consensus. Finally, after a period of mandatory silence, nodes will start consensus at an agreed point.
A separate Catchup Agent running on each node is responsible for ensuring that node’s blockchain and block proposal database are synced with the network. The catchup engine is continuously making random sync connections to other nodes whereby any node discovering that they have a smaller TIP_ID than their peer will download the missing blocks, verify supermajority threshold signatures on the received blocks, and commit them to its chain.
When the node comes online from a hard crash, it will immediately start this catchup procedure while simultaneously participating in the consensus for new blocks by accepting block proposals and voting according to consensus mechanism but without issuing its own block proposals. The reason for this is that each block proposal requires the hash of the previous block, and a node will only issue its own block proposal for a particular block id once it has finished the catch up procedure.
With such an agent running on each node, nodes having experienced a hard crash will be able to easily rejoin in block proposal after re-syncing their chains.
If you are interested in trying SKALE out, make sure to join the SKALE community on Discord and check out the Developer Documentation!
For a deeper dive into SKALE’s Technology, check out our Technical Overview and Consensus Overview.
SKALE’s mission is to make it quick and easy to set up a cost-effective, high-performance SKALE Chain that runs full-state smart contracts. We aim to deliver a performant experience to developers that offer speed and functionality without giving up security or decentralization. Follow us here on Telegram, Twitter, and Discord, and sign up for updates via this form on the SKALE website.


